How to Monitor Cron Jobs with BetaSeries Health
BetaSeries Health can monitor your cron jobs and notify you when they don't run at
expected times. Assuming curl or wget is available, you will not need to install
any new software on your servers.
The principle of operation is simple: your cron job sends an HTTP request ("ping") to BetaSeries Health every time it completes. When BetaSeries Health does not receive the HTTP request at the expected time, it notifies you. This monitoring technique, sometimes called "heartbeat monitoring", is a type of dead man's switch. It can detect various failure modes:
- The whole machine goes down (power outage, hardware failure, somebody trips on cables, etc.).
- The cron daemon is not running or has an invalid configuration.
- Cron does start your task, but the task exits with a non-zero exit code.
- The cron job runs for an abnormally long time.
Setting Up
Let's take a look at an example cron job:
# run backup.sh at 06:08 every day
8 6 * * * /home/me/backup.sh
To monitor it, first create a new Check in your BetaSeries Health account:
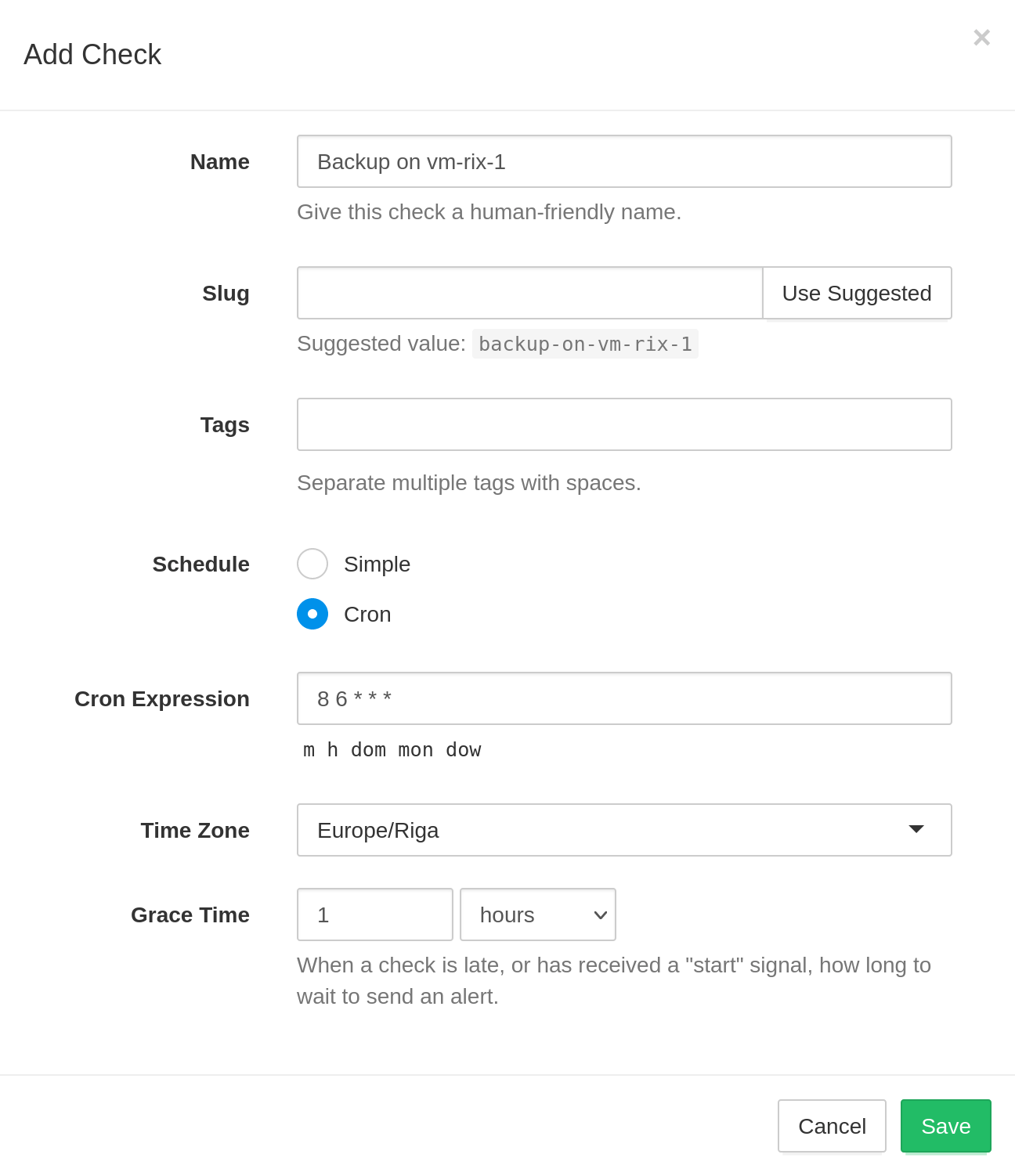
After creating the check, copy the generated ping URL , and update the job's definition:
# run backup.sh, then send a success signal to BetaSeries Health
8 6 * * * /home/me/backup.sh && curl -fsS -m 10 --retry 5 -o /dev/null https://health.betaseries.com/ping/your-uuid-here
The extra curl call lets BetaSeries Health know the cron job has run successfully. BetaSeries Health keeps track of the received pings and notifies you as soon as a ping does not arrive on time.
Note: you can alternatively add the extra curl call as a final line inside the
/home/me/backup.sh script to keep the cron job's definition clean and short.
You can use an HTTP client other than curl to send the HTTP request.
Curl Options
The extra options in the above example tell curl to retry failed HTTP requests, limit the maximum execution time, and silence output unless there is an error. Feel free to adjust the curl options to suit your needs.
- &&
- Run curl only if
/home/me/backup.shexits with an exit code 0. - -f, --fail
- Makes curl treat non-200 responses as errors.
- -s, --silent
- Silent or quiet mode. Hides the progress meter but also hides error messages.
- -S, --show-error
- Re-enables error messages when -s is used.
- -m <seconds>
- Maximum time in seconds that you allow the whole operation to take.
- --retry <num>
- If a transient error is returned when curl tries to perform a transfer, it will retry this number of times before giving up. Setting the number to 0 makes curl do no retries (which is the default). A transient error is a timeout or an HTTP 5xx response code.
- -o /dev/null
- Redirect curl's stdout to /dev/null (error messages still go to stderr).
Grace Time
Grace Time is the amount of extra time to wait when a cron job is running late before declaring it as down. Set Grace Time to be above the expected duration of your cron job.
For example, let's say the cron job starts at 14:00 every day and takes between 15 and 25 minutes to complete. The grace time is set to 30 minutes. In this scenario, BetaSeries Health will expect a ping to arrive at 14:00 but will not send any alerts yet. If there is no ping by 14:30, it will declare the job failed and send alerts.
Notifications
BetaSeries Health has integrations to deliver notifications over different channels: email, webhooks, SMS, chat messages, incident management systems, and more. You can and should set up multiple ways to get notified about job failures:
- Redundancy: if one notification channel fails (e.g., an email message gets delivered to spam), you will still receive notifications over the other channels.
- Use different notification methods depending on job priority. You can set up notifications from low-priority jobs to email only, but notifications from high-priority jobs to email, SMS, and team chat.
Additionally, to make sure no issues "slip through the cracks", in the Account Settings › Email Reports page you can configure BetaSeries Health to send repeated email notifications every hour or every day as long as any of the jobs is down:
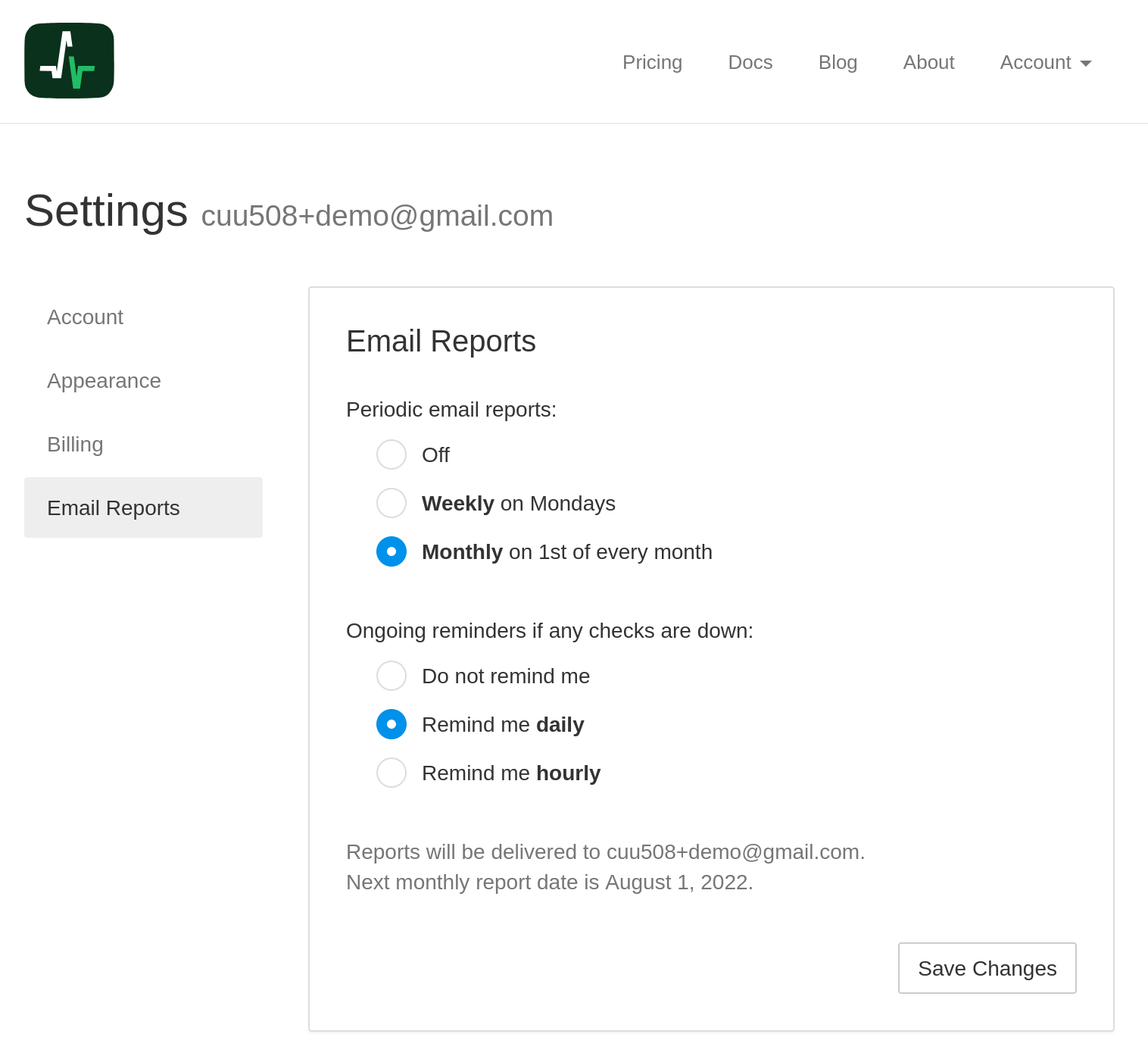
Advanced Techniques
- If your cron job hits an error, you can actively signal it to BetaSeries Health.
- You can send a "start" signal at the start of the cron job, to track its run time.
- You can send stdout and stderr output in the HTTP POST body.
What about MAILTO?
Classic cron implementations have a built-in method of notifying about cron job failures, the MAILTO variable:
MAILTO=email@example.org
8 6 * * * /home/me/backup.sh
So why not just use that? There are several drawbacks:
- For MAILTO to work, the server needs to have a configured MTA.
- You will not be notified if the whole machine is powered off or has lost network connection.
- If your cron job produces any stdout output, you will receive an email every time the job runs. This may result in alert fatigue and you not noticing errors between diagnostic messages.
Looking up Your Machine's Time Zone
If your cron job consistently pings BetaSeries Health an hour early or an hour late, the likely cause is a timezone mismatch: your machine may be using a timezone different from what you have configured on BetaSeries Health.
On modern GNU/Linux systems, you can look up the time zone using the
timedatectl status command and looking for "Time zone" in its output:
$ timedatectl status
Local time: C 2020-01-23 12:35:50 EET
Universal time: C 2020-01-23 10:35:50 UTC
RTC time: C 2020-01-23 10:35:50
Time zone: Europe/Riga (EET, +0200)
System clock synchronized: yes
NTP service: active
RTC in local TZ: no
Viewing Cron Logs Using journalctl
On a systemd-based system, you can use the journalctl utility to see system logs,
including logs from the cron daemon.
To see live logs:
journalctl -f
To see the logs from e.g. the last hour, and only from the cron daemon:
journalctl --since "1 hour ago" -t CRON